Design
Development
Research
Launch
Evolve
Extend
May 31, 2026
7 min read
summary
Enterprise web app development for product teams that need more than a vendor on a contract. Phenomenon is a web app development firm that handles enterprise app development services from architecture through launch — design, engineering, and product thinking in one place, not distributed across three agencies.
Key Takeaways:
- Enterprise app development services that default to microservices without enforcing modular boundaries first introduce compounding network latency and lose database transaction guarantees before they have solved any real scaling problem.
- The modular monolith pattern — used by Shopify to process 32 million requests per minute during peak global traffic — delivers the organizational benefits of independent team ownership without the distributed systems overhead that destroys development velocity.
- Database architecture is the ultimate bottleneck in high-scale systems: ScyllaDB’s shard-per-core, GC-free architecture reduced Discord’s p99 read latency from 40-125ms to under 15ms at the service layer while cutting cluster size from 177 nodes.
By Polina Chebanova | Co-founder May, 2026
Enterprise app development services: The Architecture Decision That Determines Everything
The first architectural decision in enterprise app development services — monolith, modular monolith, or microservices — propagates through every subsequent engineering choice the team will make for the next five years. Most organizations make this decision in the wrong direction, driven by either organizational inertia (staying with a legacy monolith past the point of maintainability) or architectural fashion (migrating to microservices before the team has the operational infrastructure to support distributed systems).
Enterprise web app development at scale is not a binary choice between these patterns. It is a continuous architectural spectrum, and the optimal position on that spectrum depends on team size, traffic volume, domain complexity, and the organization’s operational maturity. A team of 12 engineers shipping a SaaS product with 50,000 users has no business running microservices. A platform with 500 engineers and 5 million daily active users may need physical service decomposition for specific, well-bounded domains — but almost certainly not everywhere.
The web app development firm that tells every client they need microservices is optimizing for contract size, not system performance. The firms producing the highest-ROI enterprise web development outcomes in 2026 are the ones that start with a disciplined modular monolith, enforce strict domain boundaries programmatically, and scale physical infrastructure horizontally before touching the service topology.

| Architectural Driver | Monolith | Modular Monolith | Microservices |
| Operational complexity | Extremely low — single deployment unit | Low to moderate — single unit, internal boundaries | Extremely high — container orchestration, service meshes |
| Transaction integrity | Out-of-the-box ACID compliance | High — co-located modules share database transactions | Lost — requires Saga patterns and manual consistency |
| Network latency baseline | Nanoseconds — in-process execution | Nanoseconds — direct in-process calls | Compounding milliseconds — every boundary is a network hop |
| Team deployment autonomy | Low — single pipeline creates bottlenecks | Moderate — teams own modules within a monorepo | High — independent pipelines per service |
| Refactoring flexibility | High — IDE-assisted across full codebase | Moderate — strict public interfaces required | Low — schema changes require multi-service coordination |
A concrete example of microservices latency cost: a typical e-commerce transaction — authentication, inventory check, order processing, payment, notification — chains seven sequential service calls. If each inter-service network hop averages 20 milliseconds, the transaction accumulates 140 milliseconds of baseline latency before executing a single database query. This is the architectural tax of distributed systems, and it is paid on every request, by every user, every day.
Real-world benchmark: Shopify’s production infrastructure processes 32 million requests per minute during peak global shopping events. The entire platform runs on a single Ruby on Rails modular monolith with 2.8 million lines of code — not a microservices mesh. Boundary discipline is enforced by Packwerk, an open-source static analysis tool that blocks unauthorized cross-module references at compile time.
Web development firm: When to Actually Consider Microservices
A web development firm operating at enterprise scale recognizes specific signals that indicate physical service decomposition is warranted: a bounded domain with genuinely independent scaling requirements (a video transcoding service that needs 100x more compute during peak hours than the user management service), a security boundary that legally requires process isolation (PHI handling in a healthcare platform), or an organizational structure where two large teams have fundamentally incompatible release cadences for the same domain.
None of these signals apply to most enterprise web app development projects at the 100,000-to-1,000,000 user scale. The best web app development companies are transparent about this. The decision to introduce physical service decomposition should be driven by measured system behavior — actual bottlenecks, actual deployment conflicts, actual scaling requirements — not architectural aspirations.
When microservices are genuinely appropriate, the real cost is the ‘architectural tax’: distributed transaction management through Saga patterns, service mesh configuration for mutual TLS, observability infrastructure spanning multiple deployment targets, and the loss of the IDE-assisted refactoring that makes monolithic codebases easy to evolve. Development web app velocity typically drops 30-50% immediately post-decomposition, recovering only after the team has invested 3-6 months in operational infrastructure.
Web app dev company: High-Concurrency API Gateways and Edge Infrastructure
The ingress layer of a high-scale enterprise web application — the set of components that handle incoming traffic before it reaches application servers — determines whether a traffic spike produces graceful load distribution or a catastrophic failure cascade. A web app dev company building for 1M+ users must design this layer before the first application server is provisioned, not as an afterthought when the first traffic incident occurs.
The modern enterprise ingress pipeline operates in tiers. At the edge, a globally distributed Content Delivery Network (CDN) — Cloudflare, Akamai, Fastly, or AWS CloudFront — absorbs up to 80% of raw request volume through two caching mechanisms: push-based distribution of static assets to edge nodes, and pull-based retrieval-and-cache on initial client request. The CDN terminates connections at the nearest geographic edge, reducing round-trip latency and shielding origin servers from the full volume of global traffic.
Behind the CDN, Layer 4 load balancers (AWS Network Load Balancers, HAProxy) route raw TCP/UDP streams with ultra-low latency and TLS passthrough, scaling to millions of connections per second. Layer 7 application gateways (AWS Application Load Balancers, API gateways) evaluate HTTP-level protocols — path-based routing, cookie-based session stickiness, HTTP/2 multiplexing, WebSocket handling. AWS Elastic Load Balancing holds approximately 67% of the managed cloud load balancer market, which reflects both its capability and the organizational lock-in effects of building on a single cloud provider’s managed services.
| Network Component | Layer | Scaling Trigger | Primary Function |
| CDN (Cloudflare, Fastly) | Edge / Anycast | Geo-proximity, cache hit ratios | Caches static assets; absorbs DDoS; reduces origin load by up to 80% |
| Network Load Balancer | L4 Transport (TCP/UDP) | Raw connection count, bandwidth saturation | High-throughput, low-latency routing; TLS passthrough |
| Application Load Balancer | L7 Application (HTTP) | Active request count, target response time | Path/host routing; session stickiness; HTTP/2 and WebSocket handling |
| Horizontal Pod Autoscaler | Kubernetes Orchestration | CPU >70% or latency >200ms | Dynamically adjusts pod count; scales from 5 to 50 pods in under 60 seconds |
The thread execution model at the API gateway layer is a structural stability decision, not a performance optimization. Traditional blocking gateways assign a dedicated thread per connection. When downstream services experience latency spikes — database lock contention, network congestion, third-party API slowdowns — those threads block, waiting for responses. Under traffic spikes or client retry storms, the gateway’s thread pool saturates, triggering a failure cascade where health checks fail and connections drop cluster-wide.
Asynchronous, non-blocking gateways like Netflix’s Zuul 2 (built on Netty’s event loop architecture) assign a single thread per CPU core and handle all connections through callbacks. Because there is no dedicated thread per connection, the memory footprint per connection is minimal. Zuul 2 maintains persistent HTTP/2 and WebSocket connections at scale without the thread-exhaustion death spiral. Netflix’s production data shows a 25% throughput improvement in I/O-bound gateway clusters after the Zuul 1 to Zuul 2 migration — with no gain in CPU-bound clusters, which is an important nuance: the benefit is load-type dependent.
Web app development company usa: Database Architecture at Scale
The database tier is the ultimate bottleneck in any stateful, high-scale web application. Unlike application servers, which scale horizontally by adding stateless containers, databases manage physical write locks, disk I/O, and replication lag that create hard scaling ceilings. A web app development company usa operating at enterprise scale must architect the database tier before the system launches — retrofitting sharding onto a production database with millions of records is one of the most operationally dangerous engineering tasks in existence.
The foundational distinction in database scaling is between partitioning and sharding. Database partitioning is a logical division of data within a single instance: horizontal partitioning splits rows across tables (orders partitioned by year), vertical partitioning separates columns into distinct tables to reduce disk I/O per query. Database sharding is a physical split across entirely separate instances and servers — each shard holds a distinct data subset, distributing CPU, RAM, and I/O horizontally. Sharding multiplies write capacity but introduces cross-shard query complexity and eliminates the relational foreign key guarantees that single-instance databases provide.
Sharding key selection is the highest-stakes decision in database architecture. A poor sharding key creates hotspots — one shard receiving almost all writes while others sit idle. Sharding an orders table by created_at timestamp means every new order hits the newest shard. Sharding by name initials creates severe data skew based on name distribution. Range-based sharding concentrates traffic on the most recent partition. The production-grade solution is consistent hashing: mapping both servers and data keys onto a logical ring, so adding a new node requires migrating only the keys from its immediate neighbor — a minor fraction of total data, executable online without production impact.
| Sharding Strategy | Distribution Mechanism | Key Advantage | Key Drawback |
| Hash-Based Consistent Hashing | Keys route to nearest clockwise server on a logical ring | Even distribution; minimal migration when scaling cluster | Scatters related rows — range queries require multi-shard coordination |
| Range-Based Sharding | Data split by predefined value ranges (e.g., date ranges) | Simple to configure; efficient for targeted range scans | High hotspot risk — writes concentrate on the most recent partition |
| Geolocation-Based Sharding | Split by user location metadata (region codes) | Minimizes latency by routing users to nearby nodes | Severe data skew risk if user populations are geographically concentrated |
The real-world case that defines the state of the art in database scaling is Discord’s migration from Apache Cassandra to ScyllaDB for their core message storage layer — a system handling trillions of messages across hundreds of millions of users. Cassandra’s LSM-tree storage engine prioritizes write speed but makes reads expensive, requiring queries across multiple SSTables. Discord’s compound sharding key (channel ID plus time bucket) created hot partitions on high-traffic channels, causing latency spikes that cascaded through the Cassandra cluster’s Java Virtual Machine garbage collection pauses and SSTable compaction backlogs.
ScyllaDB resolved these bottlenecks through architectural fundamentals: written in C++ rather than Java, eliminating JVM garbage collection pauses entirely. Its shard-per-core architecture binds execution loops to specific CPU cores, maximizing processor cache locality and delivering consistent sub-millisecond query performance. Discord’s p99 read latency dropped from 40-125ms under Cassandra to approximately 15ms at the service layer — with the service layer itself adding only 5ms overhead due to a request coalescing layer built in Rust.
Enterprise web development: The 2026 Technology Stack for Production Systems
Enterprise web development in 2026 has converged on a specific set of technologies that balance developer velocity, type safety, and production reliability. The convergence is driven by three forces: the maturation of TypeScript as the default language for both frontend and backend, the rise of AI-assisted coding tools that generate dramatically higher-quality output against typed codebases, and the operational simplicity of managed cloud services that have absorbed infrastructure complexity that previously required dedicated platform engineering teams.
TypeScript is now the default language for serious enterprise web development — the most actively contributed language on GitHub with 2.63 million monthly contributors. The AI coding tools that have become central to development velocity (GitHub Copilot, Claude Code, Cursor) generate materially better code when analyzing typed function signatures and interfaces. Teams that maintain dynamically typed JavaScript codebases are paying a productivity penalty on every AI-assisted development task.
React dominates the frontend layer with 44.7% developer adoption, backed by the largest ecosystem of component libraries, headless UI tools, and state management utilities in the industry. Next.js extends React into a full-stack framework, blending static site generation, server-side rendering, and serverless API execution to optimize Core Web Vitals and search engine indexing simultaneously. The javascript web app development ecosystem has stabilized around this stack for enterprise use cases.
| Stack Layer | Standard Choice (2026) | Alternative | Selection Rationale |
| Frontend Framework | React 19 + TypeScript | Vue 3, SvelteKit | Largest ecosystem; best AI code generation quality; 44.7% developer adoption |
| Full-Stack Framework | Next.js 15 | Nuxt, Remix | SSR + SSG + serverless API in one framework; optimal Core Web Vitals |
| API Protocol | tRPC (monorepo) / GraphQL (multi-client) | REST + OpenAPI | End-to-end type safety; eliminates schema duplication in TypeScript stacks |
| Primary Database | PostgreSQL 17 + pgvector | MySQL (Vitess for sharding) | 55.6% professional adoption; native vector embeddings for AI/RAG pipelines |
| Caching Layer | Redis (Sharded Cluster) | Memcached | Atomic Lua scripts for rate limiting; distributed session management |
| Infrastructure | AWS + Pulumi/Terraform IaC | GCP, Azure | 67% managed load balancer market share; mature managed services |
| Observability | Loki + Grafana + Sentry | Datadog, New Relic | Cost-effective full-stack observability; real-time error tracking |
At the API layer, protocol selection depends on integration topology. tRPC is the strongest choice for monolithic or tightly coupled Next.js applications — it shares TypeScript type definitions directly between server and client, delivering end-to-end type safety without a schema generation step. GraphQL serves complex enterprise platforms with multiple client types (web, mobile, IoT) requiring different data subsets from a unified layer. REST with OpenAPI remains the standard for public-facing APIs and third-party integrations where broad interoperability matters more than type safety.
PostgreSQL remains the leading relational database for enterprise web app development, consumed increasingly via serverless autoscaling engines like Neon or Supabase for workloads with variable traffic patterns. The addition of pgvector extends PostgreSQL to store and query high-dimensional embeddings alongside transactional records, enabling RAG pipelines and AI feature development without introducing a separate vector database into the infrastructure.
Web app development firm: Reliability Patterns for High-Scale Systems
A web app development firm building for 1M+ users must implement proactive failure containment — mechanisms that prevent individual component failures from cascading into system-wide outages. The architectural risk at scale is not that components fail (they will) but that failure in one component propagates to dependent components, which propagate it further, until a single database slowdown has made the entire application unresponsive.
Distributed rate limiting is the first line of defense against resource exhaustion attacks and traffic abuse. The Sliding Window Counter algorithm divides the rate-limiting window into sub-windows (10-second sub-windows within a 1-minute limit) and calculates a weighted sum between the previous and current window to smooth boundary bursts without the excessive memory footprint of logging individual request timestamps. Clients exceeding thresholds receive an HTTP 429 Too Many Requests response with standard headers (X-RateLimit-Limit, X-RateLimit-Remaining, X-RateLimit-Reset).
Distributed rate limit counters synchronized across gateway nodes via Redis require atomic operations to prevent race conditions. Under high concurrency, a standard read-then-write counter update allows multiple gateway instances to read the same counter value before any writes the increment — creating a window where traffic above the configured limit leaks through. Redis Lua scripts execute counter checks and increments as a single serialized unit, eliminating the race condition without the latency overhead or deadlock risk of distributed locks.
The Circuit Breaker pattern prevents naive autoscaling from amplifying downstream failures. When a database saturates, application latency spikes, CPU rises, and a CPU-triggered autoscaler spins up more application instances — which immediately attempt to open more connections to the already-overwhelmed database, worsening the saturation. A circuit breaker operates as a state machine: Closed (normal operation, monitoring error rates), Open (failure rate exceeds threshold — typically 20% for critical paths — immediately returning fallback responses without hitting the downstream), Half-Open (allowing limited test requests after a recovery timeout to determine whether the downstream has recovered). This decouples the failure blast radius and gives downstream systems time to recover.
| Reliability Pattern | Vulnerability Addressed | Implementation Mechanism | Tooling |
| Distributed Rate Limiter | DDoS, brute-force, credential stuffing | Sliding Window Counter in atomic Redis Lua scripts | Nginx + Lua, Sharded Redis, API Gateways |
| Circuit Breaker | Cascading failure from downstream saturation | Closed/Open/Half-Open state machine with error rate sliding window | Envoy, Resilience4j, Zuul Gateway |
| Cache Stampede Mutex | Database saturation from simultaneous cache misses | Mutex locks or probabilistic early expiration on cache miss | Redis distributed locks, Memcached |
| Idempotent Task Queue | Double-processing of critical write events on retry | Unique message keys, deduplication tables, consumer-side checks | Apache Kafka, RabbitMQ |
Message broker selection between Apache Kafka and RabbitMQ is an architectural decision with long-term implications. Kafka appends events to a durable distributed log with configurable retention, supports consumer offset management for replay, and suits event streaming, real-time analytics pipelines, and event sourcing architectures. RabbitMQ pushes messages to consumers from transient queues that purge on acknowledgment, with sophisticated routing via exchanges and bindings — the standard for traditional background task queues, inter-service task distribution, and transactional notifications. The organizations that conflate the two and use Kafka for simple task queuing are paying unnecessary infrastructure costs; those using RabbitMQ for event sourcing are accepting data loss by design.
Web app development company usa: Use Case — AI Tutoring MVP Delivered for Scale
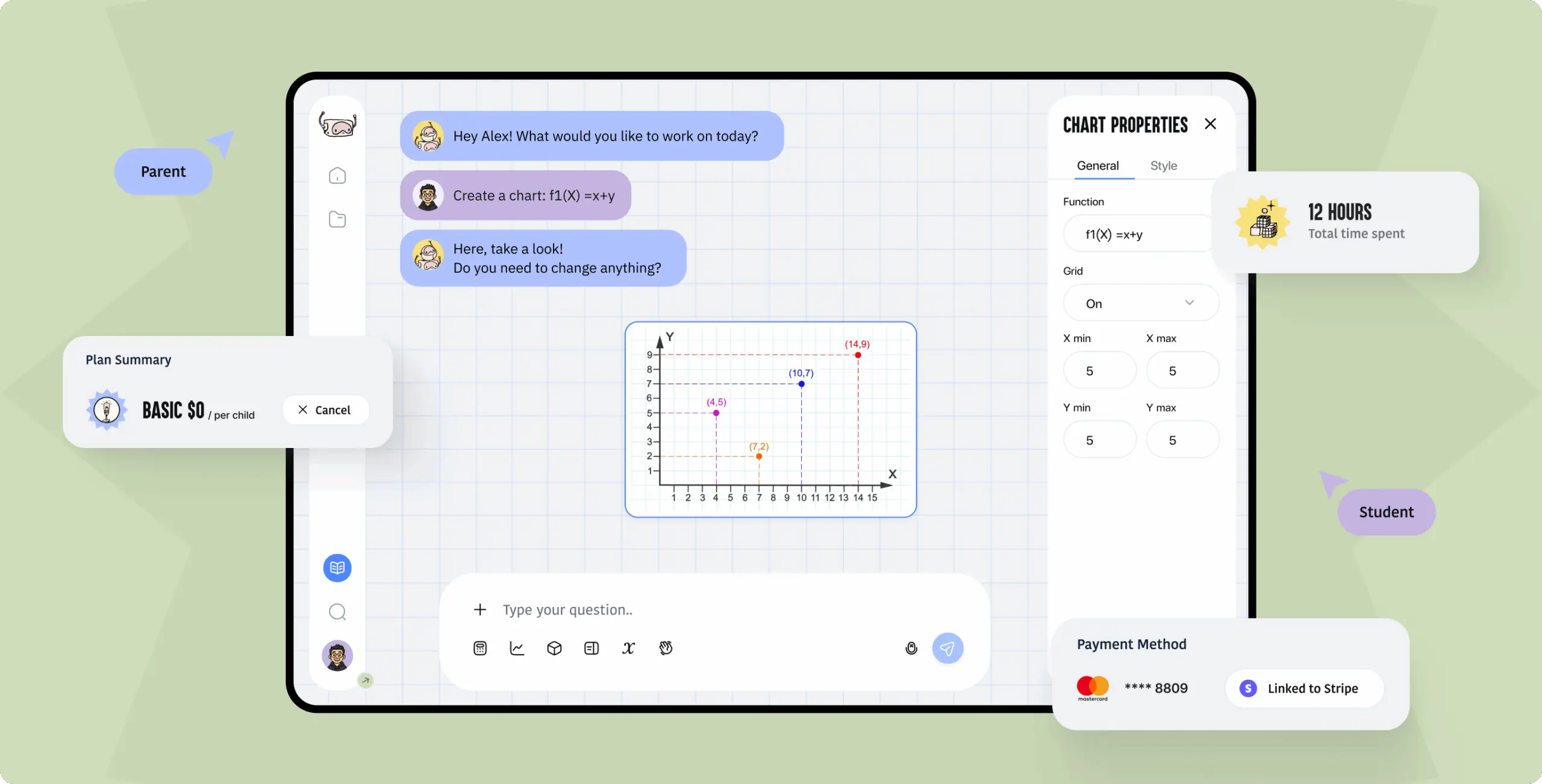
Problem:
An EdTech startup in the UAE needed to launch an AI-powered math tutoring platform for middle and high school students under tight time-to-market pressure. The MVP had to validate core product hypotheses — AI-guided learning, interactive whiteboard integration, parent oversight — without overbuilding features that had not been validated by real users. Students were losing focus mid-lesson on existing platforms, with no mechanism to resume progress. Parents had no visibility into session history or payment control. The interface needed to work for students without prior technical guidance and for parents who needed progress transparency without overwhelming operational detail.
Feature:
Phenomenon Studio designed a desktop-first web application structured around two separate, role-optimized user flows — students and parents — with distinct information architectures serving each audience’s actual tasks. The student interface combined an AI tutor chat with a dynamic whiteboard workspace, designed for continuous learning sessions with automated lesson history saving and seamless resumption. AI-powered problem recognition allowed students to upload photos of math problems for instant step-by-step analysis. The parent dashboard provided clear session history, activity insights, and subscription management in a single interface. A modular, scalable UI component system was implemented from the start, reducing future design and development cost as new features are added. The design language balanced AI-inspired minimalism with engagement signals appropriate for the teenage audience — a direction validated through three moodboard directions (White and Clean, Gamified and Immersive, Bold and Engaging) before committing to the final concept.
Result:
The platform launched ahead of schedule, enabling early student onboarding before the competitive window closed. A credible product presence was established in the EdTech niche, giving the client a strong strategic foundation for partnerships and investor conversations. The modular UI system reduced future development costs materially by enabling rapid feature expansion without rebuilding the component foundation. Timeline: focused rapid analysis cycle plus full UX/UI design and MVP architecture in a short development cycle. The platform is built to scale into a full educational platform as user validation confirms which features drive retention.
Best web app development companies: How to Evaluate a Partner for Enterprise Scale
Web development vs app development is a distinction that matters less in 2026 than it did five years ago. Modern enterprise web applications built on Next.js with React Native or Expo for mobile — sharing TypeScript business logic, API clients, and component libraries across surfaces — are effectively full-product engineering platforms. The evaluation criteria for a partner delivering this scope are the same regardless of how the engagement is labeled.
The best web app development companies operating at enterprise scale are identifiable by five operational practices that demos and portfolio reviews do not surface. First, they have a documented architecture review process that happens before any code is written — not a kickoff call, but a structured technical discovery that produces a system design document covering data architecture, infrastructure topology, and failure mode handling. Second, they can produce references from clients whose systems are in production at significant scale, not just from clients who shipped a first version.
Third, they have a position on database architecture — they can tell you precisely when to shard, which sharding strategy fits which access pattern, and how they have handled hot partition problems in production. An enterprise web app development services team that cannot articulate this does not have production experience at scale. Fourth, they maintain observability as a first-class deliverable: Loki, Grafana, and Sentry are not add-ons configured after launch — they are part of the production definition. Fifth, they have a security practice that includes zero-trust architecture, externalized authentication (Clerk, Auth0, or Kinde), and automated SOC 2 compliance tooling (Vanta or Drata) for regulated industry clients.
Web app development companies usa: Why Phenomenon Studio
Since 2019, Phenomenon Studio has delivered 200+ enterprise web applications, SaaS platforms, and AI-integrated products across Healthcare, FinTech, EdTech, and regulated enterprise markets. Our 70+ in-house engineers, architects, and designers operate in integrated sprint teams — system architect, frontend engineer, backend engineer, DevOps specialist, and QA lead in the same delivery cycle. We cover the full web application development process from architecture design through production deployment and post-launch observability.
Our web app development usa engagements span the full architectural spectrum: modular monoliths with Hexagonal Architecture and CI/CD automation for early-stage products, horizontally sharded Pod architectures for mid-scale platforms, and distributed systems with ScyllaDB, Kafka, and Rust-based service layers for high-scale enterprise workloads. We serve clients across major US markets, including web development firm new york engagements and projects in Chicago, Dallas, Houston, Miami, and New Jersey — as well as international clients across Europe, Australia, and the UK.
- Architecture-first delivery: Every engagement starts with a documented system design that covers data architecture, infrastructure topology, failure mode handling, and compliance requirements before any code is written.
- Compliance engineering: HIPAA, SOC 2 Type II, and GDPR compliance designed into system architecture from discovery — not retrofitted post-launch.
- Observability as standard: Loki, Grafana, and Sentry observability stacks deployed to production as part of the initial launch scope, not as a post-incident addition.
- Full-cycle partnership: Post-launch retainers covering performance monitoring, security patching, feature evolution, and compliance audit support — from $1,499/month for maintenance to $5,000/month for active feature development.
Phenomenon Studio pricing: Enterprise web application development engagements start from $25,000 for well-scoped MVP builds. Full-scale enterprise platforms with compliance architecture, custom database sharding, and observability infrastructure start from $80,000. Ongoing development retainers start from $2,500/month. Web app development company usa engagements recognized by Clutch as top-rated — $500M+ raised across client portfolios.
Share this opening with friends


Jul 29, 2026
9 min read
Compare the best product design agencies for SaaS startups and growth-stage companies. Learn how to choose a UX design agency, compare engagement models, pricing, and real product design case studies.

Jul 26, 2026
9 min read
Learn how to build a scalable brand system through five key phases—from discovery and strategy to visual identity, activation, and brand guidelines.
Have a project in mind?
Let's chat
Have a project to
discuss?
discuss?

Have a partnership in
mind?
mind?